Information Edge: Lessons from Building an AI Research Advantage
A genuine upgrade for navigating an ocean of research

A few years ago, I sat in a graduate seminar with a professor at the frontier of natural language processing research. At some point the conversation turned to the volume of new work being published (papers, preprints, conference proceedings) and someone asked how he kept up with all of it. He shrugged and said he had a graduate student who handled that for him.
I remember thinking: that sounds nice.
The bottleneck in serious research has never really been access to information. It’s knowing what to pay attention to. A graduate student who understands your work, your questions, and your blind spots, and who surfaces the right papers at the right time, is genuinely valuable. Most researchers don’t have one.
So I built one. I call it MARC — Multimodal Academic Research Curator.
What follows is a set of lessons from building and living with MARC over the past year. Some surprised me. All of them have changed how I think about what it means to stay current in a fast-moving field.

What MARC Does
Before the lessons, a brief orientation.
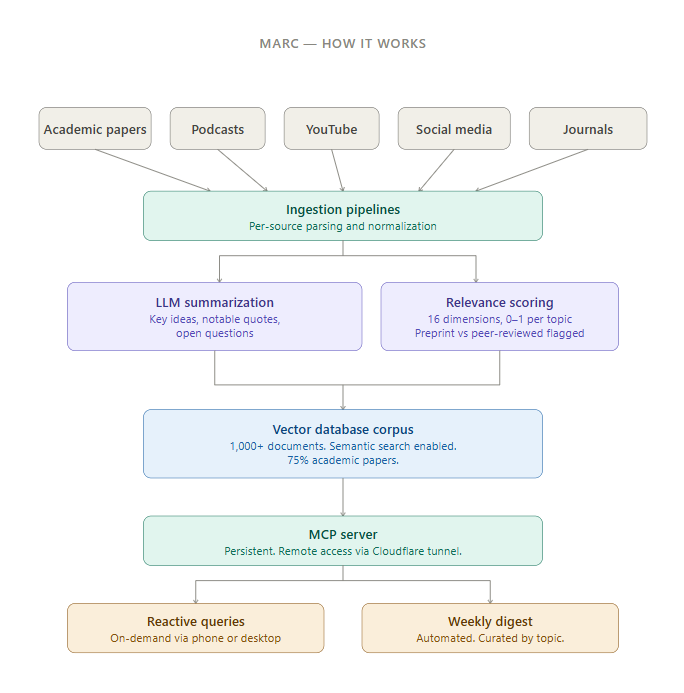
MARC ingests research from academic papers on arXiv and SSRN, academic journals, podcasts, YouTube, and selected social media. Each source is processed by a large language model that produces a structured summary: not a recap of findings, but key ideas, notable quotes, and open questions the research raises. Every source is also scored across sixteen relevance dimensions I’ve defined based on my own research interests, from quantitative finance to geopolitics to machine learning. Those scores allow filtering and retrieval that goes well beyond keyword search.
The corpus now contains well over a thousand documents, roughly three-quarters of which are academic papers. That balance matters. Social media aggregation is easy to build. Getting a system that can reason meaningfully over dense academic work is a different problem. The more interesting one.
I interact with MARC through a persistent server accessible from anywhere, including my phone. I can ask it to surface recent papers on a specific topic, review trends across the corpus, or pull the full text of something I want to examine closely. It also sends me a weekly digest, automatically curated by topic, of what’s come in over the past seven days.
With that context, here are the lessons.
1. Model Choice Is a First-Order Decision
When I started building MARC, I tested a range of language models for the summarization layer. The differences were not marginal.
The cheaper models produced summaries that were dressed-up abstracts. They could repeat findings. They could not synthesize. When I asked for key ideas from a complex paper, they surfaced what was already stated in the introduction, verbatim often. What I wanted was the kind of summary a smart reader produces after actually engaging with the work: what does this really argue, how do the pieces connect, what does this imply for adjacent problems?
Frontier models do this. Cheaper models don’t. The gap isn’t about polish. It’s a qualitative difference in reasoning. For a system whose value depends entirely on summary quality, using the wrong model would have made MARC close to useless.
There’s a broader observation here. A lot of products being sold today are wrappers around models that don’t perform at the frontier, because frontier models are expensive at scale. For large commercial deployments, that tradeoff may make sense. For an individual building a tool for their own research, the economics work out differently. The capability difference justifies the cost several times over.
2. Building a Tool Forces You to Articulate What You Care About
To build MARC’s relevance scoring system, I had to define sixteen dimensions, each specific enough that a model could score a paper on it and distinct enough that they weren’t redundant.
This was harder than I expected, and more useful.
It required honesty about what I actually research, as opposed to what I tell myself I research. Some dimensions I initially wanted to include turned out to overlap substantially with others. That forced a real question: was I distinguishing two things, or just naming the same thing twice? Others I thought were peripheral turned out to be central once I looked at my actual reading habits.
Defining the system is a form of research planning. It surfaces assumptions, clarifies what you actually care about, and produces an explicit map of your intellectual interests. That map has value well beyond the tool.
3. Multimodal Access Changes Your Relationship With Research
Early in building MARC, I added the ability to generate audio summaries and visual representations of research. I treated these as nice-to-have features. There were, in fact, more than that.
Being able to listen to a summary of recent papers while driving, or ask for a visual of how a set of ideas connect, has changed how often I engage with the system. Research is no longer something that happens only when I’m at a desk with time blocked out for it. It fits into the margins of the day.
The lesson isn’t really about audio or images. It’s that the format in which you consume information shapes whether you consume it at all. A text-only system is constrained to contexts where reading is possible. A multimodal one adapts to your life rather than requiring you to adapt to it.
4. Serendipity Can Be Engineered
The weekly digest has produced some of my most useful research leads. Not because it found what I was looking for, but because it surfaced things I wasn’t.
Recently it brought up a paper on transformer architectures using a methodology I hadn’t encountered. It came through because of its relevance score on a dimension I track, not because I searched for it. I ended up spending several hours with it, using MARC to interrogate the methodology and think through where it might apply to problems I’m working on in quantitative finance.
Cross-domain discovery, machine learning methodology finding its way into finance research, isn’t a new idea. But it’s easy to miss in practice when you’re focused on your immediate reading list. The digest creates a regular encounter with things outside your active search.
Serendipity has a reputation for being random. It doesn’t have to be.
5. Prompt Architecture Is a Design Discipline
Early versions of MARC asked the language model for a summary. The results were inconsistent, sometimes strong, sometimes shallow, and the shallow results were hard to diagnose.
The fix was decomposition. Rather than “summarize this paper,” the system now asks separately for key ideas, notable quotes, and open questions. These aren’t stylistic categories. They have different failure modes. A model that misses something in one field often surfaces it in another. The structure creates redundancy that improves reliability.
This generalizes. The way you ask shapes what you get, and careful prompt design is a form of systems design. A vague prompt produces a vague output not because the model is weak, but because the question was underspecified. That’s on the architect.
6. The Upstream Curator Still Matters
MARC is only as good as the decisions I made when building it. The sources I chose to ingest, the relevance dimensions I defined, the topics I weighted. These all reflect my priors. The system surfaces what I’ve implicitly told it to look for. It doesn’t challenge my framing from outside.
There’s a version of this technology that sounds like it replaces judgment: put the research in, get the insights out. That’s not how it works. What it does is extend judgment, amplifying the ability to act on existing research instincts across a much larger volume of material, much faster. The instincts still have to come from somewhere.
The graduate student analogy holds here too. A great research assistant extends what you can do. They don’t substitute for your understanding of what’s worth doing.
7. The Time Dimension Requires Deliberate Attention
This one took me the longest to notice.
MARC’s summaries are generally strong on content. What a piece argues, what evidence it marshals, what questions it leaves open. Where they tend to be weaker is temporal context: when something was written, what the market environment was at the time, whether a forecast proved out.
In many fields this matters less. In finance, it matters quite a bit. A paper on portfolio construction written during one rate environment carries different weight than one written in another. An interview with a practitioner making predictions requires knowing whether those predictions came before or after the relevant events.
I’ve partially addressed this through careful prompting, and the system does surface publication dates and peer-review status. But this remains an area where human judgment has to stay engaged. The model tells you what a document says. It doesn’t always situate it in time the way a careful reader would. In finance, those are sometimes very different things.
What This Adds Up To
MARC has changed how I work in ways I didn’t anticipate when I started. Literature review, historically slow and incomplete, is now systematic. The breadth of what I track has expanded without increasing the time I spend on it. The depth of engagement with individual papers has also increased. I have something to think with, not just read with.
The force multiplier framing is accurate but undersells it a little. The nature of the work has shifted. Less time managing information, more time using it.
That’s what I was jealous of when that professor mentioned his graduate student.
Until next time, stay on the cutting edge, everyone.
Appendix: A Brief Technical Note
For readers interested in how MARC is built.
The system ingests content from academic sources (arXiv, SSRN, academic journals), podcasts, YouTube transcripts, and curated social media. Each document is processed by a frontier language model that produces a structured summary with three defined fields: key ideas, notable quotes, and open questions. Every document is also scored on sixteen relevance dimensions (each a specific topic area, rated 0 to 1), which allows filtering and retrieval beyond keyword matching.
Summaries and metadata are stored in a vector database, which enables semantic search across the full corpus. Queries surface conceptually related documents even when exact terms don’t match.
The system runs through a persistent MCP (Model Context Protocol) server, accessible remotely including from a phone. This allows both reactive use, querying the corpus on demand, and proactive use in the form of the weekly digest.
The corpus is over a thousand documents, approximately 75% academic papers. The system distinguishes preprints from peer-reviewed publications, and that distinction is surfaced in responses.